doris 运维故障汇总
doris FE master卡死
FE日志最后[reportHandler.putToQueue():228] the report queue size exceeds the limit :100 .current 101
进程无响应, jstack $fe_pid > jstack.txt也无响应 。 gc也没啥异常。 端口监听在但是连不上。
暂时处理在fe.conf添加 qe_max_connection = 4096 report_queue_size = 1000 label_keep_max_second = 21600 // 6 hour streaming_label_keep_max_second = 21600 // 6 hour
看看效果。
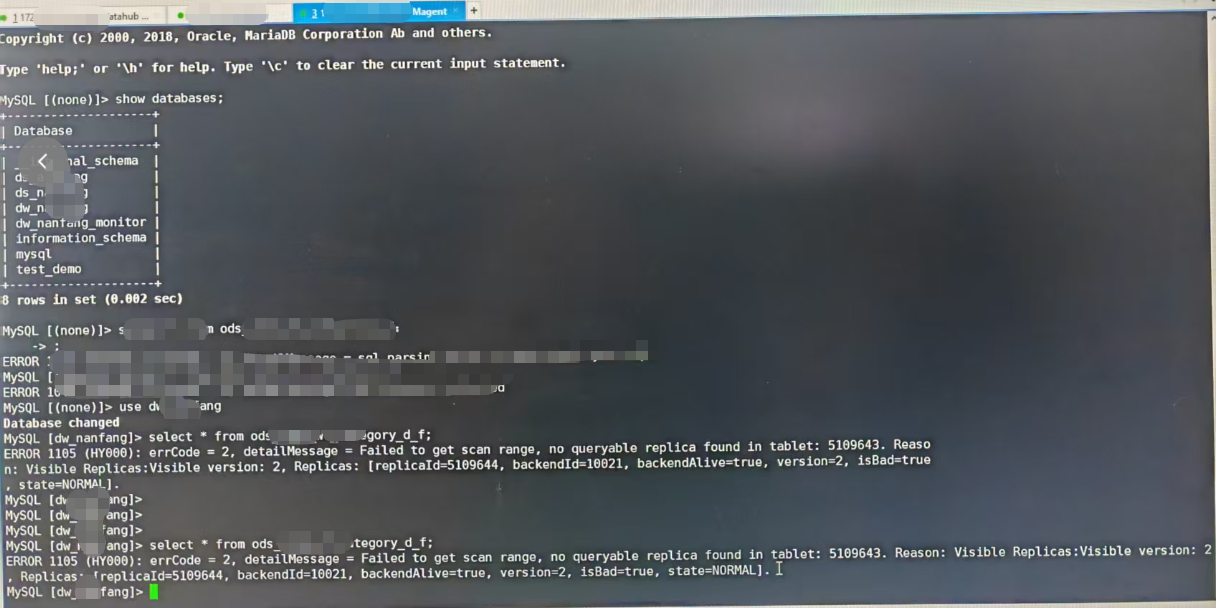
Failed to get scan range, no queryable replica found in tablet
服务器停电,数据库未提前关闭导致。建议再故障恢复前先查询一下所有有故障的表。然后再恢复表。表恢复后可以进行数据对比。将表数据恢复一致。
参考:https://doris.apache.org/zh-CN/docs/2.1/faq/sql-faq
Failed to get scan range, no queryable replica found in tablet: xxxx
###Q: Failed to get scan range, no queryable replica found in tablet: xxxx
###A:当副本无法修复时候,可以通过
####使用空白副本填补缺失副本
ADMIN SET FRONTEND CONFIG ("recover_with_empty_tablet" = "true");
#####参数关闭
ADMIN SET FRONTEND CONFIG ("recover_with_empty_tablet" = "false");
##查看表的分片
show tablets from db_name.table_name\G
#查看分片信息
show tablet tablet_id\G
#然后执行后面的 show proc 语句,查看这个 tablet 对应的副本信息,检查副本是否完整
show proc '/dbs/...........'
#显示等待迁移的 Tablet 列表。
SHOW PROC '/cluster_balance/running_tablets';
#查看均衡历史:
SHOW PROC '/cluster_balance/history_tablets';
doris be进程死掉
以下为处理过程:
1、通过调参数处理:
be日志
W20251123 15:47:07.192207 2686758 fragment_mgr.cpp:628] report error status: exchange req success but status isn't ok: [NEM_LIMIT_EXCEEDED]PStatus: (10.240.77.27)[MEM_LIMIT_EXCEEDED]PreCatCh error code:11, [E11] Allocator sys memory Check failed: Cannot alloc:8192, consuming tracker:<Query#Id-22cfefb0c08a4b4e-8a95ebc42e2c8388>, peak used 10762872000, Current used 10697598592,exec node:<>, process memory used 17.70 GB exceed Limit 56.33 GB or sys available memory 2.94 GB less than low water mark 3.13 GB.
/var/log/messages日志
/var/log/messages 日志audit: type=1701 audit(1769210012.298:474675): auid=0 uid=0 gid=0 ses=2 pid=2686357 comm=506970655F6E6F726D616C205B776F exe="/data/doris/be/lib/doris_be" sig=11 res=1
虽然日志中没有触发oom. (也有可能输出在控制台了)dmesg -T | grep -i "killed process" 也没有kill记录。
但是be日志中 sys available memory 2.94 GB less than low water mark 3.13 GB.经常出现。
看上去像be进程sig=11自己退出了。但是这种日志很多,感觉不是每一次出现都是自己退出的。应该还是系统kill了。(在 Doris 2.1.x 的某些版本中,系统内存低水位确实是硬编码为 total_memory * 0.05(5%),没有对应的可配置参数!)
临时处理方法:
# 调高脏页比例阈值(避免频繁刷盘)
vm.dirty_ratio = 10
vm.dirty_background_ratio = 5
#sysctl.conf 的min_free_kbytes设置wei2G 。不kill 进程
vm.min_free_kbytes = 2097152
# 关键:降低 cache pressure,让系统更倾向于保留可回收内存
vm.vfs_cache_pressure = 200 # 默认 100,值越大越倾向回收 dentry/inode cache
doris_be的mem_limit = 85%, 原来是90% (这个改动我感觉用处不大)
doris be参数max_sys_mem_available_low_water_mark_bytes 默认-1 为系统的5%。
可以配置crontab回收cache内存(不建议)
#!/bin/bash
# check_mem.sh
TOTAL_KB= $ (grep MemTotal /proc/meminfo | awk '{print $ 2}')
AVAILABLE_KB= $ (grep MemAvailable /proc/meminfo | awk '{print $ 2}')
THRESHOLD_KB= $ (( TOTAL_KB * 5 / 100 )) # 5%
if [ $ AVAILABLE_KB -lt $ THRESHOLD_KB ]; then
echo " $ (date): WARNING! MemAvailable ( $ ((AVAILABLE_KB/1024)) MB) < 5% of total"
# 可选:自动清理 cache
echo 1 > /proc/sys/vm/drop_caches
# 或发送告警到企业微信/钉钉
fi
64G的系统 建议将max_sys_mem_available_low_water_mark_bytes 设置为2G 。操作系统本身的vm.min_free_bytes 为5%。为3G. 也可以不修改max_sys_mem_available_low_water_mark_bytes 而将vm.min_free_bytes 为6G. 即 vm.min_free_bytes = 6291456 .这样操作系统free mem小于6G会自动回收内存。 be进程检查free mem 会大于5% 。不会自己退出。
- 如何测试?
找个be机器free mem内存小于6G的,配置
vim /etc/sysctl.conf
vm.min_free_kbytes = 6291456
##########在/etc/sysctl.conf 增加vm.min_free_kbytes = 6291456 保存后执行
sysctl -p
###然后执行free -g
可以看到free mem已经回收了很多。大于6G了
2、 查找doris be日志(peaked),找到使用内存最多的query id.查找对应的fe 日志,找到sql语句。分析sql ,让开发人员优化sql.
我找到sql后单独在生产集群跑,发现sql会挂但是be节点未挂,重复实验多次都是如此。在sql定时任务调度时,be节点挂了。
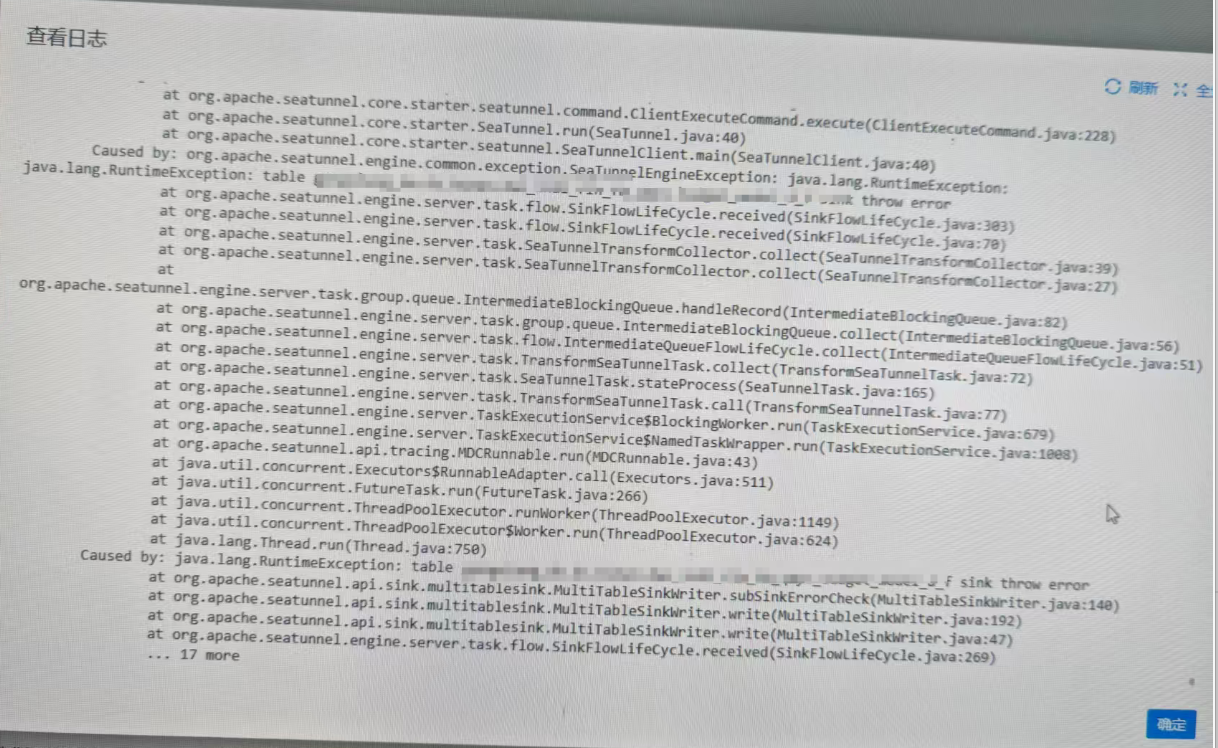
seatunnel导入doris报错1
解决方法重启doris集群
Caused by: org.apache.seatunnel.api.table.catalog.exception.CatalogException: Errorcode: [API-03], ErrorDescription: [Catalog initializefailed] - check table [] exists failed
Caused by: java.sql.SQLException: NullPointerException, msg: null
seatunnel导入doris报错2
能看到307 Temporary Redirect 这个往往是在seatunnel导入的时候fe卡了或者挂了导致的导入故障。当然还有一种可能t
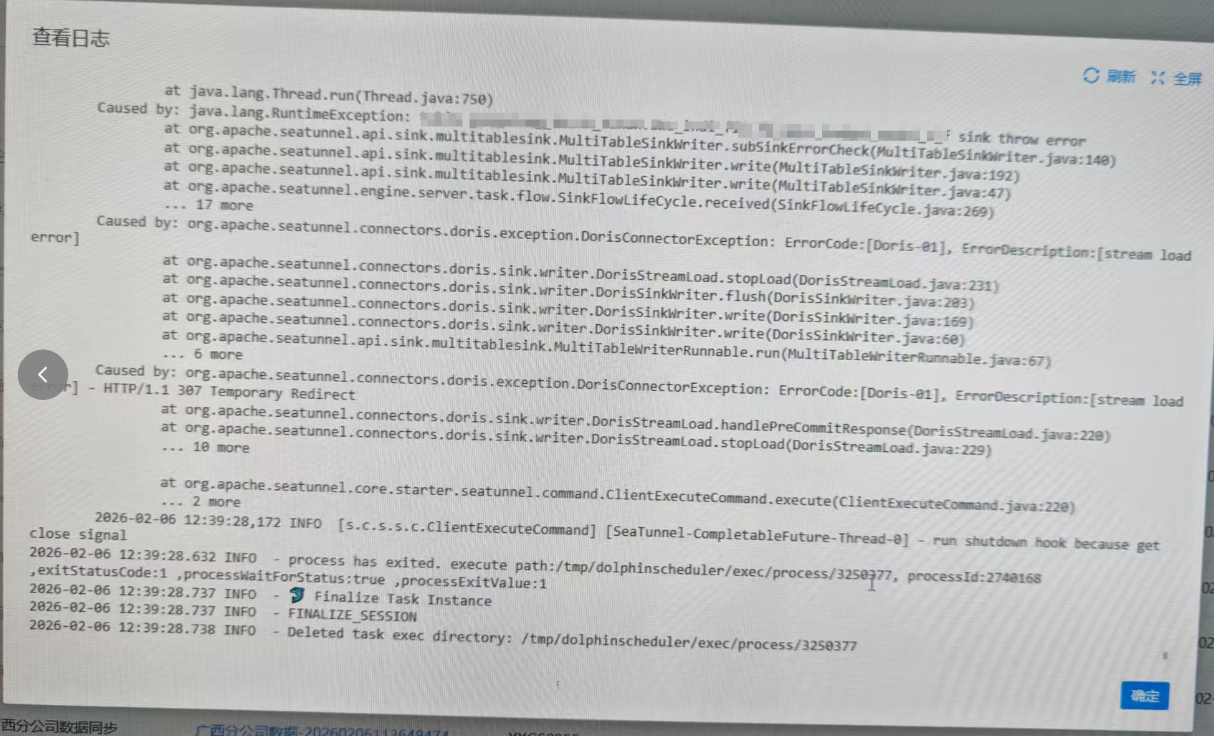
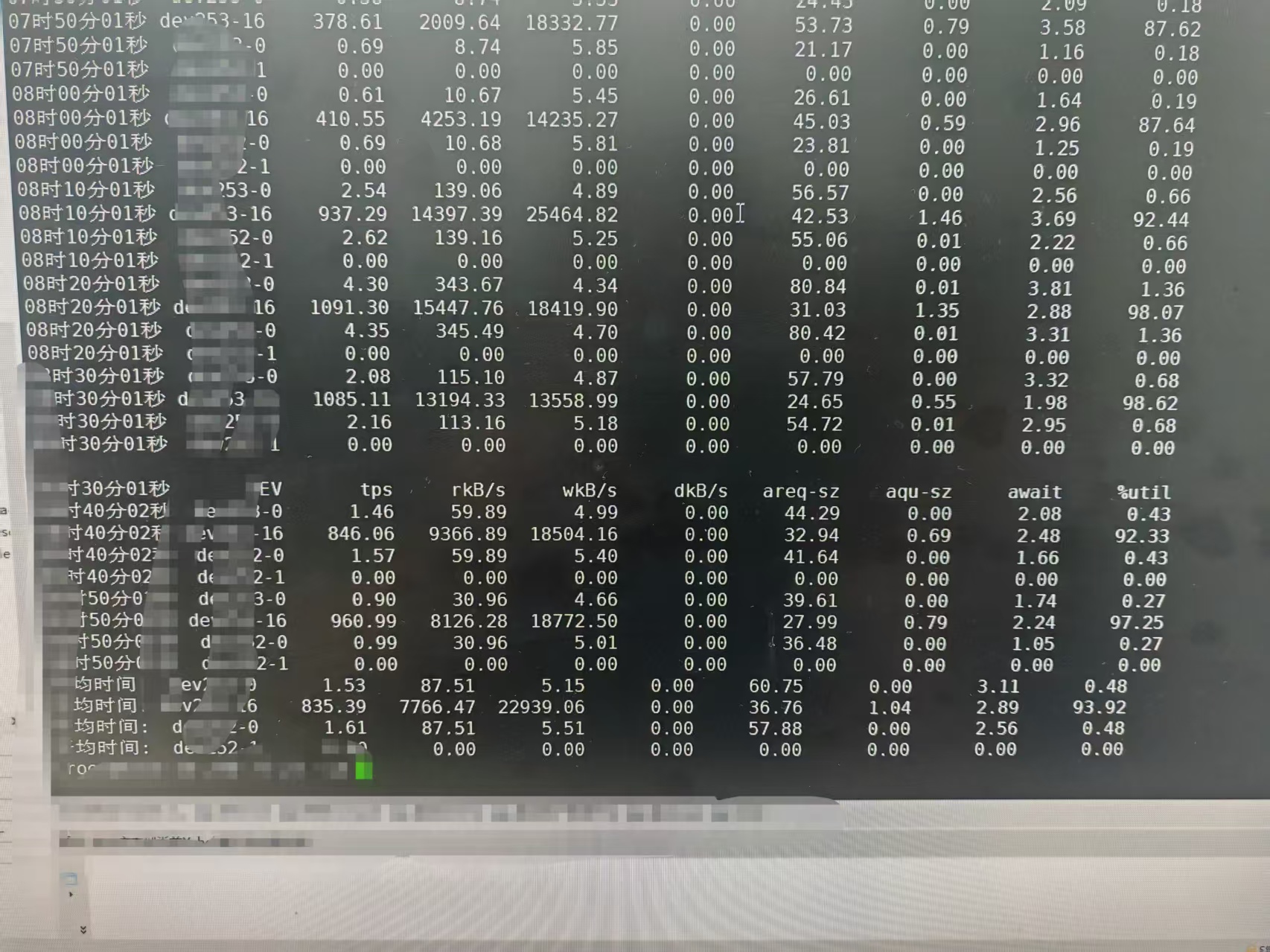
磁盘io故障导致
在不同地区有多套集群
有问题的io如下:
cat /sys/block/sda/queue/scheduler

正常机器的io如下: